
Updated 9-24-19 with new links … see postscript.
What would happen if you were named in a frivolous lawsuit? And what then if you lost, and a criminal plea bargain saved your business, your home, or perhaps even your freedom? You’d have a record. Just like that. What if you were accused of something, and the arguments were drawn out and ugly, even if you “win.”?
Depending on your state and your industry, the Attorney General, circuit court, city government, or other websites (usually high authority) could post every decision (or even accusation) for Google to crawl. If your name was even slightly unique, you’re hosed as these would almost always come up on page 1 (if not position 1) for searches under your name, even if the event occurred 10 years ago. I’m no expert on this stuff, but found my lightweight journey into this world enlightening… I encourage you to help me correct any errors here – I am not a lawyer.
So… let’s dig in just a tad….
In the Privacy Rights Clearinghouse, I skimmed a document that pre-dates Google and which sent a chill up my spine.
“The purpose of court indexes is to facilitate case location, one by one. But when the computerized indexes are merged and sorted by individual name, then what is created is essentially a criminal history, which is considered a confidential document under California law.”
Indeed, in California you must go through a request processto obtain such documents. However in some states, the information is simply posted online for anyone to see. For an enterprising individual, there are some sites which list many resources for finding lots of public records all in one place.
The document continued ….quoting a case in LA Municiple court:
“There is a qualitative difference between obtaining information from a SPECIFIC docket or on a SPECIFIED individual, [and] from obtaining docket information on EVERY person against whom criminal charges are pending in the municipal court. … It is the AGGREGATE NATURE of the information which makes it valuable to respondent; it is that same quality which makes its dissemination constitutionally dangerous.” [emphasis added] (Westbrook v. Los Angeles Co. et al., 27 Cal. App. 4th 157 (1994))
“The plaintiff was Robert Westbrook, a vendor of criminal background information doing business as Crimeline. He wanted to purchase computer tapes from the LA Municipal Court System in order to process it and resell it to interested parties. Typically, purchasers of such information are commercial information brokers, private investigators and employment background check firms. The court ruled against Westbrook in the case, citing privacy considerations. In addition, the court said that Westbrook’s use of the data over time could amount to the creation of virtual “rap sheets” on individuals. However, contrary to the Westbrook case, other courts have NOT PREVENTED unfettered access to and use of computerized public records in the aggregate.
So with search engines crawling every nook and cranny of each and every public record, indexing them, and linking them together, will we ever have “social forgiveness?” Will it ever be possible to escape a foolish or accidental mistake from the past? Is it possible for this data to be misused?
On misuse, Lauren Weinstein summed it up nicely in his blog.
True, the data is coming from state, federal, or local databases which already contain the information, but the very awkwardness of accessing these systems — in comparison to the ease of using Google — creates something of a crude firewall against at least some casual and large scale abuses, without depending solely on the quality of “sensitive information” redactions by the source agencies.
I believe that it would be extremely useful for Google to consider the implementation of additional privacy protocols particularly aimed at lowering this risk potential with public record data. A hands-off approach (treating all data equally) is unlikely to provide long-term legal protection to Google or other search engines, since it seems increasingly probable that courts will ultimately find that entities who organize data in ways that lead (however unintentionally) to abuses may share responsibility and liability for those abuses along with the data source providers.
Google’s “hands off” position is displayed on their site
“Google’s goal is to help people find the information that they seek online. If information is made publicly available, we want to help our users discover and access it. It’s the responsibility of website owners to ensure the contents of a public website — in this case, a government database — are free of information that infringes an individual’s right to privacy. In the event that a website owner needs to remove information from Google’s index, they can do so using our URL removal tool.”
But as Lauren and others also point out that Google is not the only crawler out there, and I would think that with the variations of algorithms and results pages we couldn’t police them all so the responsibility surely lies behind the robots.txt file of the information sources.
Furthermore, while individual documents may not infringe on the rights of others (e.g. public access information) the easy availability of an entire “stream” of such information may itself infringe because of the issues brought up in the California case above. A search engine results page forms such a stream, and tools such as Google Trends certainly does, though right now it takes quite a bit of traffic to register there.
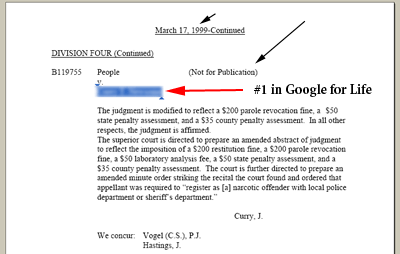
Note this simple-to-find 1999 document was marked “not for publication” and included the person’s name, which was unique and represented on a government, high-authority web page.
Is it legal for a city, state, or federal government website to keep a “stream of information about past legal events” indefinitely available on Google, arguably providing a public criminal history without any reasonable method for expungement?
What about when several years have past and someone searching the web finds such documents about you long after the “natural” expungement process has taken its course? Lawyers.com states:
With limited exception, [after expungement] you may thereafter truthfully state that you were never arrested, charged, or accused of a crime. In the eyes of the law, the entire incident never occurred. In most respects, a sealing or expungement restores you to the status you occupied before being arrested or charged.
I would think that the web effectively erases this when public records are released to the “wild” for crawling. Can search engines “sentence” you to a life sentence of reduced opportunity in social, professional, and educational pursuits?
It’s easy to ignore this issue if you’ve no history. I have no issues to worry about, but it seems there is a very, very big looming problem. As Google and other engines do a better job seeking out the corners of every document on the web, and even using our browsing histories to start spider-paths (rather than just links) we have to wonder what kinds of scary collections might happen next, and if they are going to form illegal/unconstitutional collectives.
Postscript 8/1/10: Jeffrey Rosen of the NY Times created a wonderful article called “The Web Means the End of Forgetting” that is worth your time to read. Here is an excerpt from this pc:
In addition to exposing less for the Web to forget, it might be helpful for us to explore new ways of living in a world that is slow to forgive. It’s sobering, now that we live in a world misleadingly called a “global village,” to think about privacy in actual, small villages long ago. In the villages described in the Babylonian Talmud, for example, any kind of gossip or tale-bearing about other people — oral or written, true or false, friendly or mean — was considered a terrible sin because small communities have long memories and every word spoken about other people was thought to ascend to the heavenly cloud. (The digital cloud has made this metaphor literal.) But the Talmudic villages were, in fact, far more humane and forgiving than our brutal global village, where much of the content on the Internet would meet the Talmudic definition of gossip: although the Talmudic sages believed that God reads our thoughts and records them in the book of life, they also believed that God erases the book for those who atone for their sins by asking forgiveness of those they have wronged. In the Talmud, people have an obligation not to remind others of their past misdeeds, on the assumption they may have atoned and grown spiritually from their mistakes. “If a man was a repentant [sinner],” the Talmud says, “one must not say to him, ‘Remember your former deeds.’
What are your thoughts?
Postscript
A new and well written article by Greg Sterling “Google Confronting Spain’s Right to be Forgotten” Law…appeared on Search Engine Land this week.
A new article on mugshots and long term shaming on CNN.
Opinion on how Google should crack down on the mugshot extortion sites.
Kentucky advances bill to seal records of low level felons – no mention of online residual records.
Extortion Sites in the news again targeting sex offenders and their families.




1 Comment